Your agent is brilliant and obedient — and that’s exactly the problem. It answers whatever you ask, but it never stops to notice what it doesn’t know, never chases a loose thread, and never gets smarter after the day you deployed it. The Consolidative Curiosity Architecture (CCA) is a concrete blueprint for an agent that detects its own knowledge gaps, goes looking to fill them, and folds what it learns back into its weights overnight — for roughly the price of a coffee per night. Part of our open Building Jarvis series.
Abstract
Large language models answer fluently, reason impressively, and follow instructions with startling competence—yet they do not wonder. They never pause over anomalies, pursue unanswered questions, or feel the pull of novelty. This paper argues that this absence of intrinsic inquiry is a core architectural failure, not a cosmetic limitation.
We examine six interconnected challenges: (1) the absence of intrinsic curiosity in current architectures, (2) the hierarchy of workarounds for frozen knowledge and their precise ceilings, (3) a concrete design for a curiosity-memory feedback loop, (4) the hardware and algorithmic realities of reinforcement learning on open-source 70B+ parameter models, (5) a “dream state” architecture for nightly consolidation via LoRA adapter merging inspired by hippocampal replay, and (6) the fundamental question of whether digital, quantized systems can match the information capacity of biological brains operating on chaotic substrates.
We propose the Consolidative Curiosity Architecture (CCA), provide concrete hardware specifications and cost estimates, and define an evaluation framework for measuring whether genuine self-improvement occurs. We conclude that true self-improvement in LLMs is achievable with current technology—but requires abandoning the paradigm of training as a one-time event.
The claims, in numbers
Claims from the paper, stated here without the proofs — the methodology, hardware specs, and derivations are all in the PDF.
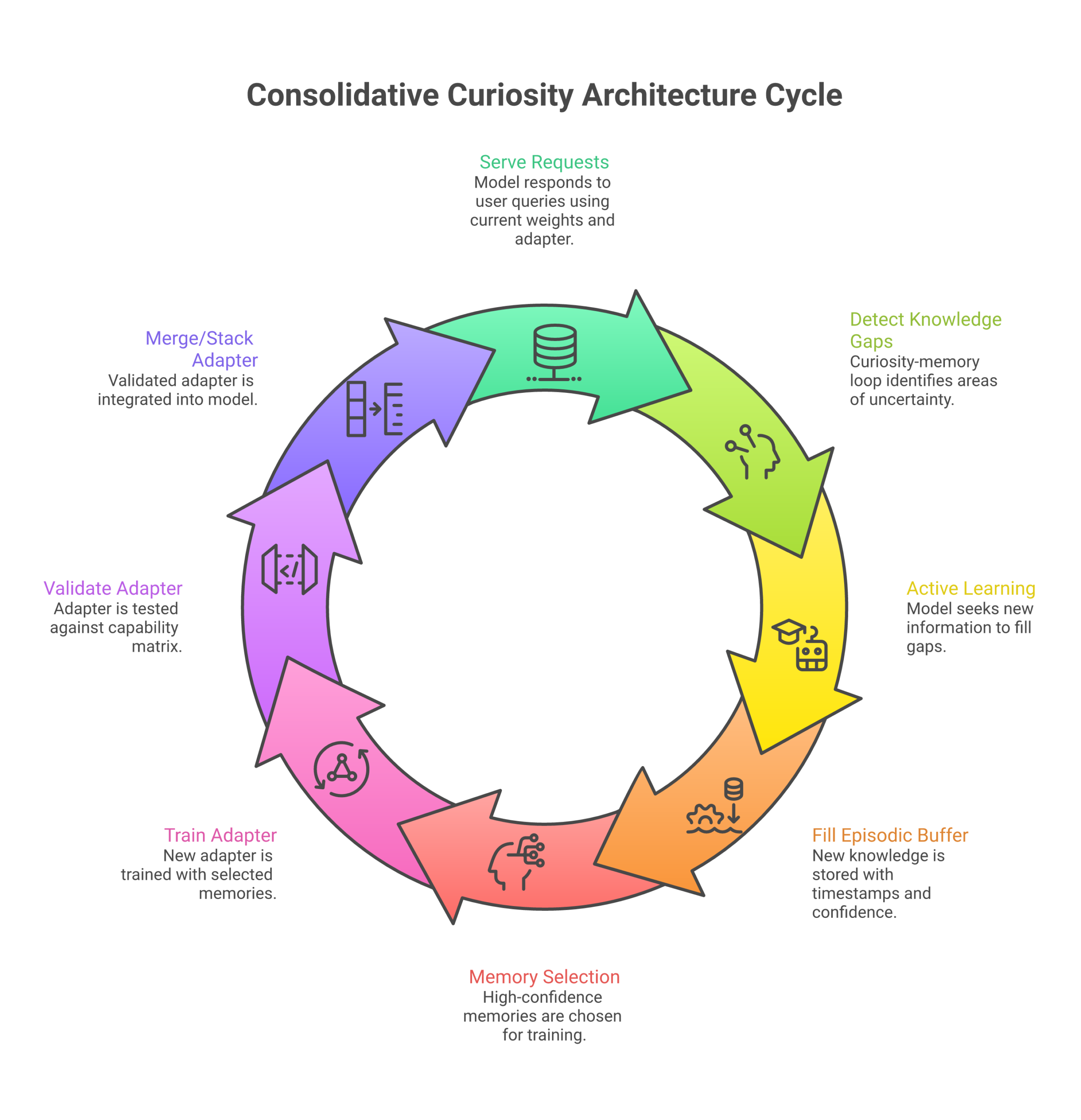
How it works, in one minute
- The frozen-model problem has a ceiling at every level. Prompting rearranges what the model already knows; RAG retrieves but never updates weights; text memory stays declarative and must be re-injected every turn; fine-tuning forgets. None of them let an agent truly learn and keep what it learned.
- Failed retrievals are curiosity signals, not errors. When the agent knows it should know something but can’t find it, that miss has precisely located a knowledge gap. The Linguistic Curiosity Module watches for these — high predictive uncertainty, or hedging like “I’m not sure” when log-probs aren’t exposed — and flags only the learnable ones.
- Unsupervised signals beat supervised heads on frozen embeddings. The learnability estimator uses k-NN novelty (AUROC 0.875) and clause-cosine incongruity (AUROC 0.896) rather than a trained classifier, because a supervised head over frozen MiniLM fell to AUROC 0.286 — below chance — on an analogous judgment task in the amygdala v3.1 experiments.
- Curiosity gets a compute budget. A fraction of the reasoning budget (1–2% for routine queries, up to 10–15% for open-ended research) is reserved for self-generated investigative queries the user never sees, logged for later consolidation.
- The agent sleeps to learn. A nightly “dream state” replays the day’s high-confidence memories into a small LoRA adapter — mirroring how the hippocampus consolidates into the neocortex during sleep — then validates against a held-out benchmark suite and rejects the adapter if any capability regresses past threshold.
- Curiosity beats scaling only where scaling can’t help. For general capability, a bigger base model wins. But for what’s specific to one deployment — your preferences, your private corpus, this agent’s recurring failures — no amount of scaling teaches a frozen model what it never saw. That’s where the nightly budget earns its keep.
Where this sits in the ecosystem
The paper situates CCA on a clear gradient with deployed open-source work that already addresses the layers below it. These tools are composable rungs on the same ladder, not competitors:
chopratejas/headroom ~24.7k ★
Reversible Compress-Cache-Retrieve: originals are cached and retrieved on demand, so the context window carries a compressed surrogate while full content stays one pointer away. Claims 60–95% token savings at near-zero accuracy delta, backed by a runnable eval suite over GSM8K, TruthfulQA, SQuAD, and BFCL.
What CCA has that headroom doesn’t: a curiosity signal mined from retrieval misses, and a path from those misses into the weights. What headroom has that CCA doesn’t: a production-grade efficiency story for retrieval. They address different walls.
addyosmani/agent-skills ~56.8k ★
Ships doubt-driven-development: a structured loop that extracts a claim to its bare artifact, submits it to a fresh-context adversarial reviewer that never saw the original reasoning, and forces reconciliation before the claim is trusted. Best-in-class prompt-level fix for the confabulation failure the paper dissects in Appendix A.
Its corrections compete for the same context window and never become instinct. That ceiling is precisely where CCA begins: prompt-level fixes the turn, weight-level fixes the instinct.
The code is open
The gateway, the skills, the echo chamber — it’s all here. Star it, fork it, break it.
Read the paper

21 pages · the full architecture, the curiosity-memory loop, hardware costs, and the evaluation framework
Was this useful?
We’re building these in the open and we want your read on them. Did this land — 👍 or 👎? What would you want the next paper to dig into? Tell us in the comments below.
More from Building Jarvis
- SALIENCE: The Death of Fixed Thresholds, the Pyramid of Significance, and Cheap Traversal as the Basis of Next-Generation Vibe Programming
- Instant Recall: A Pre-Computed Concept Index for O(1) Memory Retrieval in Persistent AI Agents
- Fractal Reasoning: Multi-Resolution Memory and Self-Similar Metacognition for LLM Agents
- Identity Persistence: Keeping an LLM Agent’s Personality Stable Across Sessions, Model Swaps, and Restarts
Leave a Reply