You keep asking “which model is best?” — and picking one. That’s the wrong question, and it’s leaving accuracy on the table. Models from different labs make different mistakes, because they were trained differently. Round Table turns that disagreement into a resource: it puts Claude, GPT, and Gemini at the same table, assigns each the role its training makes it best at, and has them argue to a synthesis — a reliability layer bolted on top of any single stochastic generator. Part of our open Building Jarvis series.
Abstract
Large language models from different providers reason differently, shaped by divergent training data, alignment objectives, and architectures. We argue that this cognitive diversity is a computational resource that can be measured, allocated, and exploited. We introduce Round Table, a framework for cross-provider adversarial deliberation in which each model is assigned the role its training-induced tendencies make it best suited to perform.
We formalize three contributions: (1) a Cognitive Diversity Index (CDI) quantifying inter-provider reasoning heterogeneity via error-vector correlation; (2) Role-Amplified Adversarial Convergence (RAAC), a 5-phase debate protocol with role assignment via bipartite matching on empirical affinity scores; and (3) Persistent Deliberation, extending single-round debate into multi-session reasoning via structured memory compaction.
A 3-model ensemble (Claude Opus, GPT-o3, Gemini 2.5 Pro) achieves 63.6% on GPQA Diamond versus a 55.6% single-model maximum — an 8 percentage-point absolute gain in a single run. Protocol validation on a 5-scenario benchmark yields CDI = 1.06 and consensus quality of 0.80. A preliminary production deployment of the Editorial Swarm pattern — parallelized cross-provider review of 8 papers with up to 24 concurrent agents — gives observational evidence of cross-provider error detection and role specialization, including a compression tendency in GPT models consistent with the long-text generation literature (Zheng et al., 2024).
The deployed implementation enforces cross-provider diversity as a configurable invariant, recovers from participant dropout rather than poisoning the synthesis, and exposes the debate choreography as a swappable orchestrator — an open deliberation substrate. This is both a theoretical framework for reasoning about cognitive diversity and a systems paper grounded in deployment; connecting the two is the contribution.
The claims, in numbers
Claims from the paper, stated here without the proofs — they’re in the PDF.
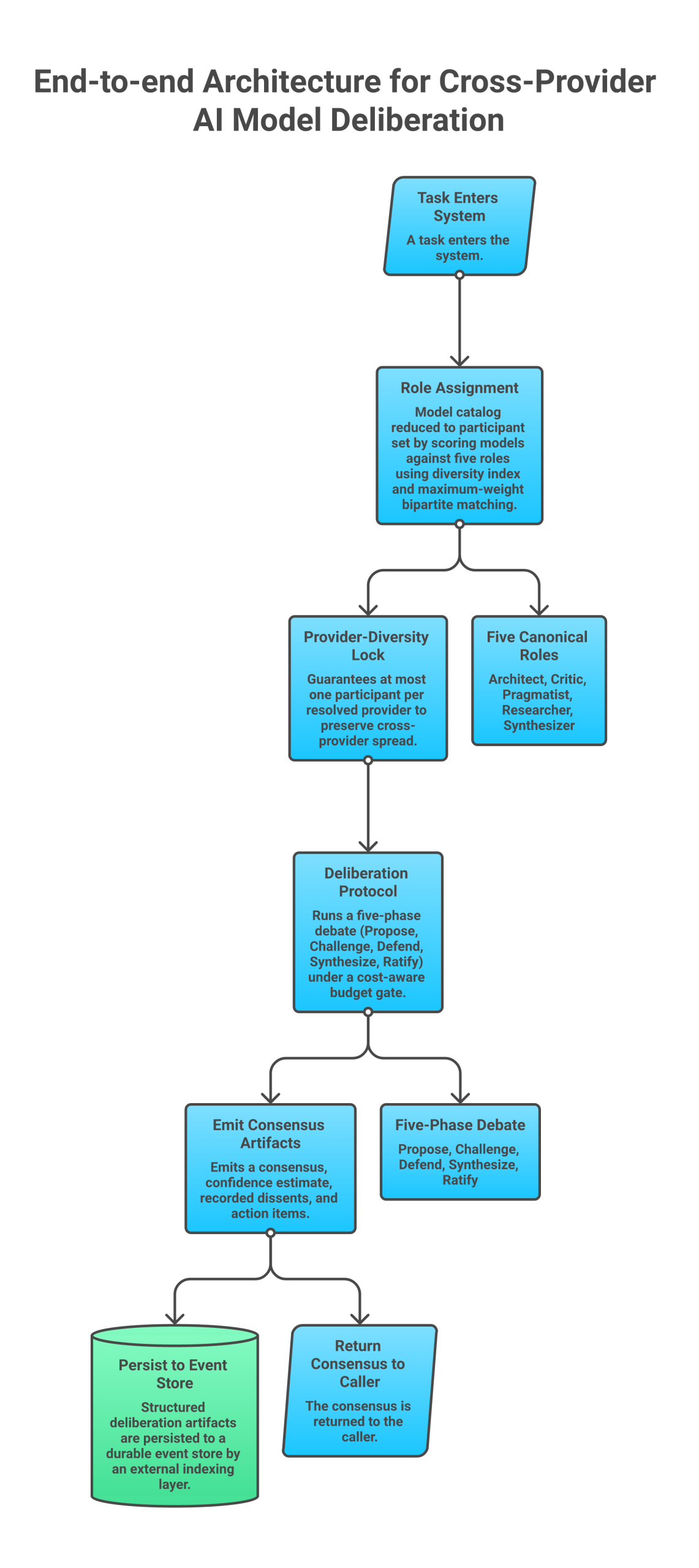
How it works, in one minute
- Measure the disagreement first. The Cognitive Diversity Index scores how differently a set of models fail — by correlating their error profiles. An ensemble that whiffs on the same questions is one point of failure wearing three faces; one that fails on disjoint questions can cover for itself. CDI = 1 means independence; above 1 means active complementarity.
- Cast models to type. Training leaves fingerprints: Claude leans reflective synthesis → Architect; GPT-class reasoners lean aggressive verification → Critic; Gemini leans real-world feasibility → Pragmatist. Round Table assigns roles by maximum-weight bipartite matching on an affinity matrix, so each model plays to its strength instead of being treated as interchangeable.
- Run a structured argument, not a vote. The RAAC protocol drives 5 phases of adversarial debate with a ratification step — built specifically to stop a persuasive-but-wrong model from talking the group into a bad answer.
- Lock in the diversity, survive the dropout. The deployed system enforces a cross-provider mix as a hard invariant (if a provider is missing, the role reroutes to a different vendor rather than silently collapsing to one). If a participant drops mid-debate, it degrades instead of poisoning the synthesis.
- Remember across sessions. Persistent Deliberation compacts each debate into the ratified consensus plus the live dissents — stored as structured artifacts, not raw transcripts — so reasoning carries across sessions without blowing up the context window.
In the ecosystem
Round Table v8.5 names two large open-source projects as composable neighbors — not competing approaches. Both sharpen the framework in ways the paper is explicit about.
⭐ headroom (chopratejas/headroom · ~24.7k stars)
Reversible Compress-Cache-Retrieve (CCR) for agent context: content-type-aware compressors shrink material in-context while caching the originals so the model can retrieve them on demand. Reports near-zero accuracy delta at 60–95% token savings across GSM8K, TruthfulQA, SQuAD, and BFCL.
Round Table v8.5 adopts headroom’s reversibility contract for debate-trace compaction: the propose/challenge/defend exchange is now cached behind a retrieval pointer instead of discarded outright, so past debates can be re-adjudicated by a disjoint judge. The two systems are complementary — headroom is content-type-aware but deliberation-blind; Round Table’s compaction is schema-aware (unresolved tensions, ratification provenance, per-model calibration) but, until this revision, one-directional.
⭐ agent-skills / doubt-driven-development (addyosmani/agent-skills · ~56.8k stars)
A discipline-oriented skill collection whose doubt-driven-development workflow is the strongest single-provider instantiation of the adversarial-challenge mechanism RAAC claims is irreducibly cross-provider. It runs: CLAIM → EXTRACT (artifact + contract, original reasoning chain stripped) → DOUBT (fresh-context adversarial reviewer with no access to the producing chain of thought) → RECONCILE → STOP (trivial-findings test + 3-cycle cap).
The paper names it the right competitor: it manufactures review diversity through context isolation rather than cross-provider error-decorrelation. Round Table has what doubt-driven-development doesn’t: a measured CDI showing errors are genuinely decorrelated (Σ ≈ 0.38) plus a ratification vote that structurally defends against the Persuasion Paradox. doubt-driven-development has what RAAC lacks: an explicit reasoning-stripped handoff and a principled STOP criterion. Round Table v8.5 identifies both as a priority ablation and as a discipline to incorporate into RAAC’s Challenge phase.
🔗 Built in the open — explore the code
Round Table is part of tinkerclaw, an open-source persistent AI agent runtime. Star it, fork it, or read the source.
Read the paper

22 pages · the CDI formalism, the RAAC protocol, the affinity matrix, GPQA evaluation, and the production deployment
Was this useful?
We’re building these in the open and we want your read on them. Did this land — 👍 or 👎? Which combination of models would you put at your round table? Tell us in the comments below.
More from Building Jarvis
- SALIENCE: The Death of Fixed Thresholds, the Pyramid of Significance, and Cheap Traversal as the Basis of Next-Generation Vibe Programming
- Instant Recall: A Pre-Computed Concept Index for O(1) Memory Retrieval in Persistent AI Agents
- Fractal Reasoning: Multi-Resolution Memory and Self-Similar Metacognition for LLM Agents
- Identity Persistence: Keeping an LLM Agent’s Personality Stable Across Sessions, Model Swaps, and Restarts
Leave a Reply