Your AI agent nails the task — then a context window later, it has forgotten the one hash, file path, or decision that actually mattered. Most agents “compact” old context by summarizing it, which quietly throws the precise details away for good. Total Recall takes the opposite approach: it treats the context window as a cache over a durable store, evicts old detail to disk instead of summarizing it, and leaves a tiny recoverable pointer behind — so nothing is ever lost. This is the first paper in our open Building Jarvis series on giving agents real, persistent memory.
Abstract
Persistent LLM agents must preserve precise strings, causal chains, and decision rationales across sessions that routinely exceed context limits. The industry-standard approach — narrative compaction — replaces this high-resolution state with lossy prose summaries, creating an irrecoverable “only copy” failure.
We present Total Recall, a lossless, event-sourced memory architecture that treats the context window as a managed cache over a durable store. Instead of summarizing, it evicts history via pointer-based compaction — compact time-range markers with topic hints and retrieval directives — while keeping all evicted content recoverable through a recall(query) tool. Retrieval is task-conditioned: what gets re-injected depends on the active task, not just embedding similarity. A write-reconciliation step keeps total memory bounded along both axes — the in-context cache and the long-term store.
The TRACE production implementation validates these claims across controlled benchmarks and months of real deployment.
The claims, in numbers
Claims from the paper, stated here without the proofs — the methodology, benchmarks, and derivations are all in the PDF.
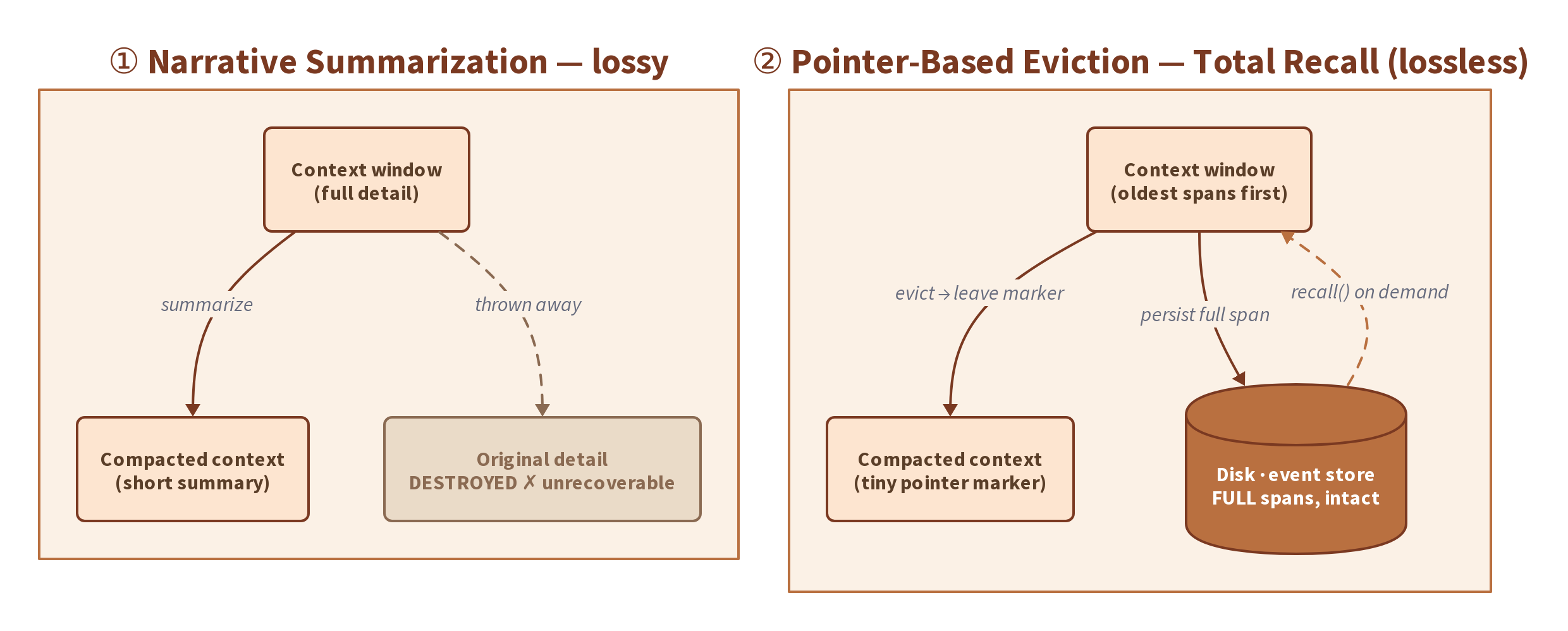
Evict, don’t summarize
The whole idea fits in one picture. Summarization shrinks the context window by collapsing old turns into a short prose summary — and the original detail is gone for good, with the summary now the only surviving copy. Pointer-based eviction shrinks it by moving old spans out to a durable store on disk and leaving a compact pointer behind. The context gets smaller either way — but only one of them can give the detail back.
When does it evict — continuously, or only when full?
Only under pressure. Eviction fires when the context window nears its budget, not on every turn and not on a timer. That’s a deliberate contrast with narrative compaction, which keeps the window continuously full of summary prose that has to be re-read every single turn. Total Recall instead holds a small, fixed working set — a “push pack” of roughly 2K tokens (the live task state, the pointer markers, and the most recent turns) — and only reaches for evicted detail on the turns that actually need it.
What gets evicted first — and why
A context window isn’t one blob; it’s a stack of typed events, and they are not equally worth keeping. Total Recall ranks them and evicts the oldest, highest-weight spans first (an LRU-style policy, with the live task state acting as an oracle for what’s about to be needed):
| What’s in the context | Evicted… | Why |
|---|---|---|
| Tool results (API dumps, file reads, search output) | first | Biggest by far, and recover cleanly via recall() |
| Tool calls | next | Reconstructable from the result + dialogue |
| Agent / user messages | under pressure | Carry intent — evicted only when needed |
| Artifact references | rarely | Already a pointer — little to gain |
| System prompt · persona · task state · markers | never | Load-bearing — guarded out entirely |
The best candidates are tool results: in a typical agent session they’re the bulk of the tokens and almost never needed verbatim again, so evicting them frees the most room for the least loss — and they come back exactly via recall() if they’re ever needed. The agent’s identity and current objective are never touched.
What’s the price you pay?
Nothing is free, so here’s the honest cost:
- An occasional lookup. When the agent needs evicted detail, it pays one
recall()round-trip (on the order of 10K tokens) — but only on the ~22% of turns that actually need it. Narrative summaries, by contrast, charge a recap tax on every turn, whether the detail is used or not. - Durable storage that grows linearly. The append-only event store grows O(T) with the conversation — no quadratic summary-of-summaries bloat.
- Near-zero compaction overhead. Choosing and evicting a span is sub-millisecond (1.46 ms measured at 200 events); marker bookkeeping stays tiny (markers merge, bounding their footprint).
Net: for the common case where most evicted content is never re-touched, this is cheaper in steady state than carrying summaries forever — and it’s lossless, which summaries can never be.
Where Total Recall sits in the ecosystem
Two recent open-source projects are the closest comparison points, and the v7.6 paper positions Total Recall against both.
headroom (Chopra, 24.7k ★) — in-place compression vs. pointer eviction
headroom arrives at Total Recall’s core thesis from the opposite direction: it caches the original content and has the model retrieve it on demand — structurally the same “context window as cache over a lossless store” insight. The difference is granularity. headroom compresses content in place: a degraded-but-addressable representation stays resident in the window while the original is cached. Total Recall evicts the span entirely behind a fixed-size pointer and recovers byte-exact on demand. headroom wins when the evicted content is re-touched often enough that a resident proxy earns its keep; Total Recall wins when most evicted content is never re-touched — the common case — since the pointer costs only tens of tokens regardless of span size. The two are composable: compress before evicting for spans likely to be re-touched, pointer-evict the rest.
doubt-driven-development (Osmani, addyosmani/agent-skills, 56.8k ★) — the metacognitive gate above storage
Total Recall guarantees that evicted content is recoverable. It does not guarantee the agent will try to recover it, or recognize that a weak result is insufficient. The binding constraint in production was not storage loss but query formulation: the agent accepted a low-similarity result instead of reformulating. doubt-driven-development is a general claim-verification loop — CLAIM → DOUBT (fresh-context adversarial re-examination) → RECONCILE → STOP — that binds to exactly the interface Total Recall exposes: recall(query) returns similarity scores so the metacognitive gate can decide whether to retry. The relationship is explicit in the paper: Total Recall is the recoverable substrate, doubt-driven-development is the documented shape of the gate above it.
The three-way steady-state cost comparison (narrative summary vs. lossy in-place compression vs. pointer compaction) is in §7.3 of the paper. The short version: narrative pays a growing recap tax on every turn; in-place compression pays a smaller recurring re-read tax; pointer compaction pays a tiny marker cost every turn and a recall() cost only on the 22% of turns that need evicted detail.
It generalizes beyond dialogue
One concrete result from §6.1 of the v7.6 paper: the same pointer-eviction principle applied to a 44-entry marketing skill catalog collapsed always-resident token cost from ~915 tokens to ~130 tokens — a 7× reduction — with no loss of reachability across all 44 entries. A single router pointer in context; the full skill body injected only when needed. The same economics as evicting a dialogue span: a fixed-size resident anchor instead of a large always-loaded block, with on-demand retrieval handling the rest. Skills, tool schemas, workspace files — anything that can be fetched on demand instead of pre-loaded is subject to the same analysis.
The TRACE implementation is part of Building Jarvis, an open series on persistent agent memory. Follow the work and contribute at github.com/globalcaos/tinkerclaw.
Read the paper

18 pages · the full architecture, the eviction policy, benchmarks, and the TRACE implementation
Was this useful?
We’re building these in the open and we want your read on them. Did this land — 👍 or 👎? What would you want the next paper to dig into? Tell us in the comments below.
More from Building Jarvis
- SALIENCE: The Death of Fixed Thresholds, the Pyramid of Significance, and Cheap Traversal as the Basis of Next-Generation Vibe Programming
- Instant Recall: A Pre-Computed Concept Index for O(1) Memory Retrieval in Persistent AI Agents
- Fractal Reasoning: Multi-Resolution Memory and Self-Similar Metacognition for LLM Agents
- Identity Persistence: Keeping an LLM Agent’s Personality Stable Across Sessions, Model Swaps, and Restarts